We were recently contacted by a client of ours, as a few months after his new website was launched he arrived into work one morning to find an empty inbox where there would normally be 20-50 enquiries. Panic!
The first thing he did was check Google UK to see if he was still at the top for all of his terms, what he found was quite disturbing.
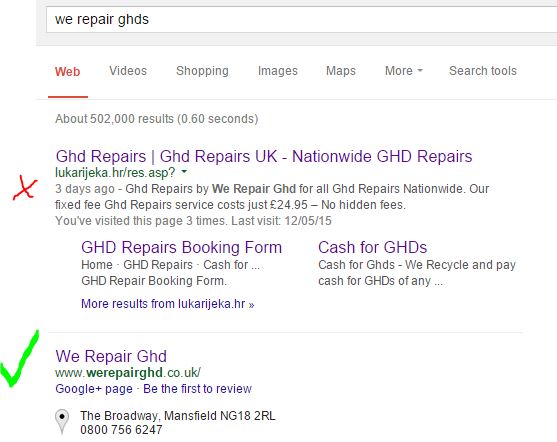
Oh dear.
He had found this information out before he contacted us, and the first thing we suspected when he was explaining what had happened was a hacked website. It was quite concerning as this was one of our new Locul websites and the security measures we have on that far outweigh anything we’ve used on any other site before – but we started looking and scanning the framework to try and find any issues.
…Nothing!
We scratched our heads a bit more, and then started doing some deep digging until Olly B found a blog post on Moz.com about Post-Panda issues. It talks about website scrapers outranking you for your own content. Nail on the head!!
Our search then went a bit deeper and we trawled every Google forum post about this issue, every user that raised it seemed to be ridiculed by the staff/contributors on there and the issue was simply fobbed off as being a case of these smaller websites not having enough authority, and that’s “just how things work now”.
What absolute rubbish.
We had to take matters into our own hands, so to begin with, we ripped apart what they had done and mapped out exactly how their Google exploit worked.
- If you viewed the site using a normal browser you were redirected to the front page of 1 store selling fake GHDs.
- If you changed content on the correct website, the hacked scraper site showed the content instantly – this means its technically not scraped, but instead is showing the pages off his site in real-time.
- If you viewed the site as Googlebot you could browse an entire copy of the website, with all meta info (canonical URLs etc) and every internal link changed to their hacked domain.
They are able to do this thanks to the Panda update, Google now sees this hacked website as being the originator of the content on my clients website, so was in fact penalising the correct website for having duplicate content. Just writing it out makes me shake my head in disbelief that Google could screw up so badly!
Now we know what they are doing, and why it’s working, we sat and thought of a few methods we can try to hopefully resolve the situation.
Method 1 – Block them with .htaccess
We trawled the access logs for my customers website, and found the IP address for the hacked website recorded every time their site accessed his.
Next, we added this into the .htaccess file;
order allow,deny
deny from 185.3.195.10
allow from all
Due to point 3 above, if the site was now accessed as Googlebot you were greeted with a blank white page and no content.
What this should hopefully do is get Google to remove the hacked website from its index as technically it now doesn’t have the same (duplicate) content as my customer. Fingers crossed!
Method 2 – Redirect the redirect?!
If Step 1 doesn’t work, or if we’re simply faced with another hacked website replacing this one then we’ll try something a bit different. The only reason we’ve not done this method already is we’re concerned that Google may penalise him even further as we will have to do something that is technically a bit frowned upon – but then it’s only mimicking what these guys are doing and they’re still managing to hold on to my clients top spot!
We would write a meta redirect into the header of my clients website that would contain an if statement (of sorts);
If the IP address of the request is [insert offending IP address(es)] then forward the request to a new page/site we create, which in the same breath redirects the user back to the page they originally requested on my clients website. Its a bit mind-melting just trying to write it down but the theory works and it basically reverses what they’ve done to actually redirect traffic in the first place.
This method could cause lasting damage to our client’s Google placement but is one of the only options we’ve got if they simply keep swapping the hacked high authority website, and Google do not de-index them so my client never pops back into the rankings.
Method 3 – Right to be Forgotten!
This method is probably the most bonkers – and due to the complexity of this attack/hack/exploit i’m personally very worried that by doing this we inadvertently get my clients website fully removed from Google, but if we have to try one last thing it will be this.
As the content on the scraped/hacked/exploited website is being copied “live” from my client’s, any content we put on there will appear on their site instantly.
So, if we then add some sensitive personal info like my clients actual signature – they will then copy it – and we can then request Google remove their website from the SERPs based as they’ll have broken the rules and should then fall within the criteria for a “Right to be forgotten” ruling.
Bonkers idea though, right?
Conclusion?
This isn’t really a proper conclusion as the issue still remains – but to conclude this blog post….. I think it’s important to highlight how damaging this kind of hack/attack/exploit could be for some people. Fortunately this client had a backlog of work, and also utilises other methods to drum up business. I was in a meeting today and the company I was with have clients that employ 100+ people, have locations around the world – and they get 100% of their business from Google.
Can you imagine how detrimental that could be to them, and their employees? Wow.. Scary really!
I hope our methods listed above work, and I hope that anyone else trying them has some success in resolving the issues they are having. Hopefully Google will step in and stop this from being possible – it never used to be possible so it must be something they can resolve.
If you are experiencing problems like i’ve described here but have no idea who to turn to then call us on 01623 650333 and ask for Olly – or send us an email using the form on our contact page.
Good luck.
EDIT: 22:12 23/05/2015 – Google Panda Problem Update: Placement Restored 🙂
We’ve been keeping our eyes on the SERPs and it seems that our clients website has regained its positions and everything seems to be back to normal. We never needed to use Steps 2 or 3 but they are worth bearing in mind in case you don’t have much luck with the first approach.
We hope this helps anyone looking for Google Panda Recovery information, please help spread the word by sharing the article to your friends and colleagues. Thanks!
Leave a Reply